Какая информация может содержаться в базе данных

Запрос «БД» перенаправляется сюда; см. также другие значения.
Ба́за да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)[1].
Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий[2].
Проблемы определения[править | править код]
В литературе предлагается множество определений понятия «база данных», отражающих скорее субъективное мнение тех или иных авторов, однако общепризнанная единая формулировка отсутствует.
Определения из международных стандартов и национальных стандартов, разработанных на основе международных:
- База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.[3][4][5]
- База данных — совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, которая поддерживает одну или более областей применения[6].
Определения из авторитетных монографий:
- База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей[7].
- База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия[8].
- База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации[9].
В определениях наиболее часто (явно или неявно) присутствуют следующие отличительные признаки[10]:
- БД хранится и обрабатывается в вычислительной системе.
Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются. - Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе.
Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции[11]. - БД включает схему, или метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).
В соответствии с ГОСТ Р ИСО МЭК ТО 10032-2007, «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определённых с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных»[3].
Из перечисленных признаков только первый является строгим, а другие допускают различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
История[править | править код]
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком смысле понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.)[12], узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты[12].
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных Кобол была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Кодда.
Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Эдгар Ф. Кодд также получил премию Тьюринга.
Сам термин база данных (англ. database) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных компанией SDC в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы[13].
Виды баз данных[править | править код]
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных»[7], по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных[править | править код]
Примеры:
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
Классификация по среде постоянного хранения[править | править код]
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.
В оперативную память СУБД помещает лишь кэш и данные для текущей обработки. - В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.
Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация по содержимому[править | править код]
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная
- Клиентская.
Классификация по степени распределённости[править | править код]
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
- Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД[править | править код]
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
Сверхбольшие базы данных[править | править код]
Сверхбольшая база данных (англ. Very Large Database, VLDB) — это база данных, которая занимает чрезвычайно большой объём на устройстве физического хранения. Термин подразумевает максимально возможные объёмы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Количественное определение понятия «чрезвычайно большой объём» меняется во времени. Так, в 1997 году самой большой в мире была текстовая база данных Knight Ridder’s DIALOG объёмом 7 терабайт[14]. В 2001 году самой большой считалась база данных объёмом 10,5 терабайт, в 2003 году — объёмом 25 терабайт[15]. В 2005 году самыми крупными в мире считались базы данных с объёмом хранилища порядка сотни терабайт[16]. В 2006 году поисковая машина Google использовала базу данных объёмом 850 терабайт[17].
К 2010 году считалось, что объём сверхбольшой базы данных должен измеряться по меньшей мере петабайтами[16].
В 2011 году компания Facebook хранила данные в кластере из 2 тысяч узлов суммарной ёмкостью 21 петабайт[18]; к концу 2012 года объём данных Facebook достиг 100 петабайт[19], а в 2014 году — 300 петабайт[20].
К 2014 году по косвенным оценкам компания Google хранила на своих серверах до 10—15 эксабайт данных в совокупности[21].
По некоторым оценкам, к 2025 году генетики будут располагать данными о геномах от 100 миллионов до 2 миллиардов человек, и для хранения подобного объёма данных потребуется от 2 до 40 эксабайт[22].
В целом, по оценкам компании IDC, суммарный объём данных «цифровой вселенной» удваивается каждые два года и изменится от 4,4 зеттабайта в 2013 году до 44 зеттабайт в 2020 году[23].
Исследования в области хранения и обработки сверхбольших баз данных VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 года проходит ежегодная конференция International Conference on Very Large Data Bases («Международная конференция по сверхбольшим базам данных»). Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment (Фонд целевого капитала «VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области сверхбольших БД и смежных областях.
См. также[править | править код]
- Архитектура ANSI — SPARC
- База знаний
- Большие данные
- Информационная система
- Модель данных
- Проектирование баз данных
- Хранилище данных
- База данных заднего плана
- Шифрование базы данных
Примечания[править | править код]
- ↑ Гражданский кодекс РФ, ст. 1260
- ↑ «Следует отметить, что термин база данных часто используется даже тогда, когда на самом деле подразумевается СУБД. […]Такое обращение с терминами предосудительно». — К. Дж. Дейт. Введение в системы баз данных. — 8-е изд. — М.: «Вильямс», 2006, стр. 50.
«Этот термин (база данных) часто ошибочно используется вместо термина ‘система управления базами данных’». — Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002., стр. 460.
«Среди непрофессионалов […] путаница возникает при использовании терминов „база данных“ и „система управления базами данных“. […] Мы будем строго разделять эти термины». —
Кузнецов С. Д. Основы баз данных: учебное пособие. — 2-е издание, испр. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007, стр. 19. - ↑ 1 2 ГОСТ Р ИСО МЭК ТО 10032-2007: Эталонная модель управления данными (идентичен ISO/IEC TR 10032:2003 Information technology — Reference model of data management)
- ↑ ГОСТ 33707-2016 (ISO/IEC 2382:2015) Информационные технологии (ИТ). Словарь
- ↑ ISO/IEC TR 10032:2003 — Information technology — Reference Model of Data Management (англ.). www.iso.org. Дата обращения 9 июля 2018.
- ↑ ISO/IEC 2382:2015 — Information technology — Vocabulary (англ.). www.iso.org. Дата обращения 9 июля 2018.
- ↑ 1 2 Когаловский М. Р., 2002.
- ↑ Дейт К. Дж., 2005.
- ↑ Коннолли Т., Бегг К., 2003.
- ↑ Мирошниченко Е. А. К формальному определению понятия «база данных» // Пробл. информатики. 2011. № 2. С. 83-87.
- ↑ Важно понимать, что структурированность базы данных оценивается не на уровне физического хранения (на котором все данные представлены совокупностями битов или байтов), а на уровне некоторой логической модели данных.
- ↑ 1 2 Грей, Дж. Управление данными: прошлое, настоящее и будущее
- ↑ Haigh T. How Data Got its Base: Information Storage Software in the 1950s and 1960s // IEEE Annals of the History of Computing. — 2009. — #4 October-December
- ↑ Very Large Database
- ↑ Riedewald M., Agrawal D., Abbadi A. Dynamic Multidimensional Data Cubes for Interactive Analysis of Massive Datasets // In: Encyclopedia of Information Science and Technology, First Edition, Idea Group Inc., 2005. ISBN 9781591405535
- ↑ 1 2 «Экстремальные» базы данных: Самые большие и самые быстрые, 2010 г.
- ↑ Alex Chitu. How Much Data Does Google Store?, 2006
- ↑ Shvachko, Konstantin. Apache Hadoop. The Scalability Update (англ.). — 2011. — Vol. 36, no. 3. — P. 7—13. — ISSN 1044-6397.
- ↑ Josh Constine. How Big Is Facebook’s Data? // TechCrunch, 23.08.2012
- ↑ Wiener, J., Bronson N. Facebook’s Top Open Data Problems, 22.10.2014
- ↑ Colin Carson. How Much Data Does Google Store? Архивная копия от 15 сентября 2016 на Wayback Machine, 2014
- ↑ Ася Горина. Увеличивающийся объем генетических данных стал проблемой для науки
- ↑ Executive Summary: Data Growth, Business Opportunities, and the IT Imperatives
Литература[править | править код]
- Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. — ISBN 5-8459-0788-8 (рус.) 0-321-19784-4 (англ.).
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. — ISBN 5-8459-0384-X.
- Date, C. J. Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с. — ISBN 978-1-59059-746-0, 1-59059-746-X.
- Date, C. J. Database in Depth. — O’Reilly, 2005. — 240 с. — ISBN 0-596-10012-4.
- Beynon-Davies P. (2004). Database Systems 3rd Edition. Palgrave, Basingstoke, UK. ISBN 1-4039-1601-2
Ссылки[править | править код]
- CITForum — материалы на сайте Центра информационных технологий
- Very Large Data Base — Endowment Inc.
- ACM SIGMOD — Association for Computing Machinery: Special Interest Group On Management of Data.
3.3. Хранение информации. Базы и хранилища данных
Предметная область какой-либо деятельности — часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес-результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие — это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется: множеством объектов и процессов, использующих объекты; множеством пользователей, имеющих различные взгляды на предметную область; данными, которые описывают объекты и процессы предметной области.
Эти данные отражают динамичную внешнюю и внутреннюю среду предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища — базы данных.
База данных, БД (Data Base) — структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы (
рис.
3.2).
Понятие «динамически обновляемая БД» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствие с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) — специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
СУБД часто упрощённо или ошибочно называют «базой данных». Нужно различать набор данных (собственно БД) и программное обеспечение, предназначенное для организации и ведения баз данных (СУБД).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специаль-ном словаре базы данных.
Организация структуры БД формируется, исходя из следующих соображений:
- адекватность описываемому объекту/системе — на уровне концептуальной и логической модели;
- удобство использования для ведения учёта и анализа данных — на уровне так называемой физической модели.
Виды концептуальных и логических моделей БД:
- картотеки;
- сетевые;
- иерархические;
- реляционные;
- дедуктивные;
- объектно-ориентированные;
- многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf-форматах приложений Excel, Access, либо в специализированном формате конкретной СУБД. Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в её рамках — таблица, табличное пространство, сегмент, куб, кластер и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных. Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные, пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных — база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение).
Теория реляционных баз данных была разработана доктором Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают как отдельные данные, так и таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц.
Кратко особенности реляционной базы данных можно сформулировать следующим образом:
- данные хранятся в таблицах, состоящих из столбцов («атрибутов») и строк («записей»);
- на пересечении каждого столбца и строчки стоит в точности одно значение;
- у каждого столбца есть своё имя, которое служит его названием, и все значения в одном столбце имеют один тип;
- запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
- строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов (Structured Query Language — SQL). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. Вопреки существующим заблуждениям, SQL является информационно-логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре. Язык SQL делится на три части:
- операторы определения данных;
- операторы манипуляции данными (insert, select, update, delete);
- операторы определения доступа к данным.
Основные функции системы управления базами данных:
- управление данными во внешней памяти (на различных носителях);
- управление данными в оперативной памяти;
- журналирование изменений и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
Обычно современная СУБД содержит следующие компоненты (
рис.
3.3):
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД.
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Рис.
3.3.
Основные компоненты СУБД
По типу управляемой базы данных СУБД разделяются на: иерархические, реляционные, объектно-реляционные, объектно-ориентированные, сетевые.
По архитектуре организации хранения данных:
- локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
- распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД:
- файл-серверные;
- клиент-серверные;
- трехзвенные;
- встраиваемые.
Файл-серверные СУБД. Архитектура «файл-сервер» не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. «Файл-сервер» только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор, и каждый новый клиент добавляет вычислительную мощность сети. Минус — высокая загрузка сети. На данный момент файл-серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird, In-terbase, MS SQL Server, Oracle, DB2, PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком двухзвенной клиент-серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес-логику реализуют в программах, запускаемых на серверах приложений. При этом модернизация обычно затрагивает только сервер приложений, а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД — это, как правило, «библиотека», которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных — например, геоинформационные системы (Geographic Informational System — GIS). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL.
В общем случае СУБД могут быть классифицированы в системе координат {Неоднородность — Автономность — Распределенность} (
рис.
3.4).
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных — это не просто место, куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать — времени на поиск нужных данных будет уходить всё больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо «очищать» и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
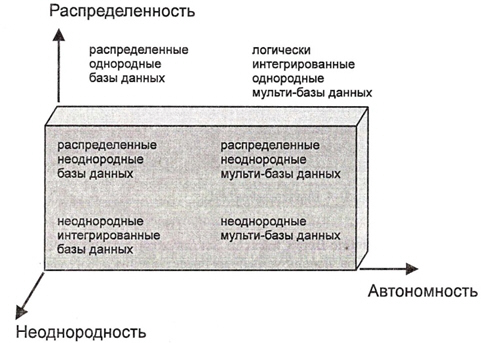
Рис.
3.4.
Классификация СУБД в системе НАР
Индустрия создания баз данных и СУБД берет свое начало в 60-х годах прошлого века и к настоящему времени достаточно развита, однако понятие «хранилище данных» в современном понимании его появилось относительно недавно. Идея хранилищ данных оказалось востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
- в более дешевых данных;
- в точных и структурированных данных;
- в большей оперативности получения и обработки данных;
- в интегрированных данных.
К концу 80-х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы «хранилищами информации» (Information Warehouse — IW). И лишь в 90-е годы, с выходом книги Билла Инмона, хранилища получили свое нынешнее наименование «хранилища данных» (Data Warehouse — DW) [25].
Б. Инмон определил хранилища данных как «предметно-ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений«.
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
- интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
- тематическое и временнОе структурирование, согласование и агрегирование;
- разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям — предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (табл. 3.3 (3.3.1)).
| Предметная ориентированность | Все данные о некоторой сущности (бизнес-объекте, бизнес-процессе и т. д.) из некоторой предметной области собираются из множества различных источников. Эти данные очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме |
| Интегрированность | Все данные о различных бизнес-объектах, взаимно согласованы и хранятся в едином общекорпоративном хранилище |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю за период вре-мени, достаточный для выполнения задач бизнес-анализа, прогнозирования и подготовки принятия решения |
| Неизменяемость | Исходные (исторические) данные после того, как они были согласованы, вери-фицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение — предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных (Distributed Data Mart — DDM). Поэтому в классическом исполнении хранилище данных было, прежде всего, репозиторием (сквозной базой данных) данных и информации предприятия.
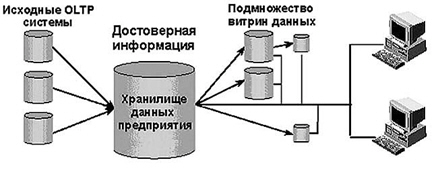
Рис.
3.5.
Схема организации данных в хранилище
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций.
С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных (
рис.
3.5).
Достоинствами архитектуры классического хранилища данных являются:
- общая семантика;
- централизованная, управляемая среда;
- согласованный набор процессов извлечения и бизнес-логики использования;
- непротиворечивость содержащейся информации;
- легко создаваемые по шаблонам и наполняемые витрины данных;
- единый репозиторий метаданных;
- многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме этого, при фильтрации, агрегировании и рафинировании «сырых» данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес-анализе.
В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Trans-actional Processing — OLTP), репозитория и витрин, должно иметь соответствующее пространство для организации «сырых» данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing — OLAP).