Какими свойствами обладает метод повторного прогона всех тестов

Главная / Программирование /
Основы тестирования программного обеспечения / Тест 11
Упражнение 1:
Номер 1
Можно ли гарантировать безопасность метода
регрессионного тестирования в условиях отсутствия
информации об изменениях в программе?
Ответ:
 (1) нет 
 (2) да 
Номер 2
При создании очередной версии программы была добавлена
функция A, функция D была удалена, функция C – изменена, а
функция U – оставлена без изменений. К какой группе
относится тест, покрывающий только функцию A?
Ответ:
 (1) тесты, пригодные для повторного использования 
 (2) тесты, требующие повторного запуска 
 (3) устаревшие тесты 
 (4) новые тесты 
Номер 3
Какие методы регрессионного тестирования применяются в
условиях высоких требований к качеству программного
продукта?
Ответ:
 (1) метод повторного прогона всех тестов 
 (2) случайные методы 
 (3) безопасные методы 
 (4) методы минимизации 
 (5) методы, основанные на покрытии кода 
Номер 4
Какими свойствами обладает метод повторного прогона всех тестов?
Ответ:
 (1) полнота 
 (2) точность 
 (3) эффективность 
 (4) универсальность 
Упражнение 2:
Номер 1
Можно ли гарантировать безопасность метода
регрессионного тестирования в условиях отсутствия тестов,
использовавшихся при тестировании предыдущих версий
программы?
Ответ:
 (1) нет 
 (2) да 
Номер 2
При создании очередной версии программы была добавлена
функция A, функция D была удалена, функция C – изменена, а
функция U – оставлена без изменений. К какой группе
относится тест, покрывающий только функцию D?
Ответ:
 (1) тесты, пригодные для повторного использования 
 (2) тесты, требующие повторного запуска 
 (3) устаревшие тесты 
 (4) новые тесты 
Номер 3
Какие методы регрессионного тестирования применяются в
условиях отсутствия программных средств поддержки
регрессионного тестирования?
Ответ:
 (1) метод повторного прогона всех тестов 
 (2) случайные методы 
 (3) безопасные методы 
 (4) методы минимизации 
 (5) методы, основанные на покрытии кода 
Номер 4
Какими свойствами обладает метод random(50)?
Ответ:
 (1) полнота 
 (2) точность 
 (3) эффективность 
 (4) универсальность 
Упражнение 3:
Номер 1
Можно ли гарантировать безопасность метода регрессионного тестирования в условиях отсутствия информации о покрытии кода тестами?
Ответ:
 (1) нет 
 (2) да 
Номер 2
При создании очередной версии программы была добавлена
функция A, функция D была удалена, функция C – изменена, а
функция U – оставлена без изменений. К какой группе
относится тест, покрывающий только функции C и U?
Ответ:
 (1) тесты, пригодные для повторного использования 
 (2) тесты, требующие повторного запуска 
 (3) устаревшие тесты 
 (4) новые тесты 
Номер 3
Какие методы регрессионного тестирования применяются, если
исходный набор состоит из структурных тестов?
Ответ:
 (1) метод повторного прогона всех тестов 
 (2) случайные методы 
 (3) безопасные методы 
 (4) методы минимизации 
 (5) методы, основанные на покрытии кода 
Номер 4
Какими свойствами обладает метод минимизации с
использованием средства поддержки регрессионного
тестирования, ориентированного на язык Java, если время его
работы оценивается как O(|P|2)?
Ответ:
 (1) полнота 
 (2) точность 
 (3) эффективность 
 (4) универсальность 
Упражнение 4:
Номер 1
Расходы на внедрение метода выборочного регрессионного тестирования…
Ответ:
 (1) равны расходам на внедрение метода повторного прогона всех тестов 
 (2) больше расходов на внедрение метода повторного прогона всех тестов 
 (3) меньше расходов на внедрение метода повторного прогона всех тестов 
 (4) могут быть больше или меньше расходов на внедрение метода повторного прогона всех тестов 
Номер 2
Время тестирования при использовании метода выборочного регрессионного тестирования (с учетом времени работы самого метода)…
Ответ:
 (1) равно времени тестирования при использовании метода повторного прогона всех тестов 
 (2) больше времени тестирования при использовании метода повторного прогона всех тестов 
 (3) меньше времени тестирования при использовании метода повторного прогона всех тестов 
 (4) может быть больше или меньше времени тестирования при использовании метода повторного прогона всех тестов 
Номер 3
В среднем, метод выборочного регрессионного тестирования…
Ответ:
 (1) обнаруживает столько же ошибок, сколько и метод повторного прогона всех тестов 
 (2) обнаруживает больше ошибок, чем метод повторного прогона всех тестов 
 (3) обнаруживает меньше ошибок, чем метод повторного прогона всех тестов 
 (4) может обнаруживать больше или меньше ошибок, чем метод повторного прогона всех тестов 
Упражнение 5:
Номер 1
Сопровождение какого типа соответствует случаю реализации новых требований пользователя?
Ответ:
 (1) корректирующее 
 (2) адаптивное 
 (3) усовершенствующее (прогрессивное) 
Номер 2
Сопровождение какого типа соответствует случаю исправления ошибки в коде?
Ответ:
 (1) корректирующее 
 (2) адаптивное 
 (3) усовершенствующее (прогрессивное) 
Номер 3
Сопровождение какого типа соответствует случаю улучшения временных характеристик программы?
Ответ:
 (1) корректирующее 
 (2) адаптивное 
 (3) усовершенствующее (прогрессивное) 
Аннотация: Рассматриваются случайные методы, безопасные методы, методы минимизации, методы, основанные на покрытии кода. Также рассматривается интеграционное регрессионное тестирование и регрессионное тестирование объектно-ориентированных программ.
Случайные методы
Когда из-за ограничений по времени использование метода повторного прогона всех тестов невозможно, а программные средства отбора тестов недоступны, инженеры, ответственные за тестирование, могут выбирать тесты случайным образом или на основании «догадок», то есть предположительного соотнесения тестов с функциональными возможностями на основании предшествующих знаний или опыта. Например, если известно, что некоторые тесты задействуют особенно важные функциональные возможности или обнаруживали ошибки ранее, их было бы неплохо использовать также и для тестирования измененной программы. Один простой метод такого рода предусматривает случайный отбор предопределенного процента тестов из T. Подобные случайные методы принято обозначать random(x), где x — процент выбираемых тестов.
Случайные методы оказываются на удивление дешевыми и эффективными. Случайно выбранные входные данные могут давать больший разброс по покрытию кода, чем входные данные, которые используются в наборах тестов, основанных на покрытии, в одних случаях дублируя покрытие, а в других не обеспечивая его. При небольших интервалах тестирования их эффективность может быть как очень высокой, так и очень низкой. Это приводит и к большему разбросу статистики отбора тестов для таких наборов. Однако при увеличении интервала тестирования этот разброс становится значительно меньше, и средняя эффективность случайных методов приближается к эффективности метода повторного прогона всех тестов с небольшими отклонениями для разных попыток. Таким образом, в последнем случае пользователь случайных методов может быть более уверен в их эффективности. Вообще, детерминированные методы эффективнее случайных методов, но намного дороже, поскольку выборочные стратегии требуют большого количества времени и ресурсов при отборе тестов.
Если изменения в новой версии затрагивают код, выполняемый относительно часто, при случайных входных данных измененный код может в среднем активироваться даже чаще, чем при выполнении тестов, основанных на покрытии кода. Это приведет к увеличению метрики количества отобранных тестов для случайных наборов. Наоборот, относительно редко выполняемый измененный код активируется случайными тестами реже, и соответствующая метрика снижается. При уменьшении мощности множества отобранных тестов падает эффективность обнаружения ошибок.
Когда выбранное подмножество, хотя и совершенное с точки зрения полноты и точности, все еще слишком дорого для регрессионного тестирования, особенно важна гибкость при отборе тестов. Какие дополнительные процедуры можно применить для дальнейшего уменьшения числа выбранных тестов? Одно из возможных решений — случайное исключение тестов. Однако, поскольку такое решение допускает произвольное удаление тестов, активирующих изменения в коде, существует высокий риск исключения всех тестов, обнаруживающих ошибку в этом коде. Тем не менее, если стоимость пропуска ошибок незначительна, а интервал тестирования велик, целесообразным будет использование случайного метода с небольшим процентом выбираемых тестов ( 25-30% ), например, random(25).
Вернемся к примеру регрессионного тестирования функции решения квадратного уравнения. Случайный метод, такой, как random(40), может отобрать для повторного выполнения любые 2 теста из 5. Например, если будут выбраны тесты 4 и 5, изменения формата вывода на экран не будут протестированы вовсе, что вряд ли может устроить разработчика.
При использовании другого случайного метода — метода экспертных оценок — в данном случае наиболее вероятен выбор всех тестов, так как затраты на прогон невелики. Однако при регрессионном тестировании больших программных систем, когда повторный прогон всех тестов неприемлем, эксперт вынужден отсеивать некоторые тесты, что также может приводить к тому, что часть изменений не будет протестирована полностью.
Безопасные методы
Метод выборочного регрессионного тестирования называется безопасным, если при некоторых четко определенных условиях он не исключает тестов (из доступного набора тестов), которые обнаружили бы ошибки в измененной программе, то есть обеспечивает выбор всех тестов, обнаруживающих изменения. Тест называется обнаруживающим изменения, если его выходные данные при прогоне на P’ отличаются от выходных данных при прогоне на P:  . Тесты, активизирующие измененный код, называются выполняющими изменение.
. Тесты, активизирующие измененный код, называются выполняющими изменение.
Выбор всех выполняющих изменение тестов является безопасным, но при этом отбираются некоторые тесты, не обнаруживающие изменений. Безопасный метод может включать в T’ подмножество тестов, выходные данные которых для P и P’ ни при каких условиях не отличаются. Поскольку не существует методики, кроме собственно выполнения теста, позволяющей для любой P’ определить, будут ли выходные данные теста различаться для P и P’, ни один метод не может быть безопасным и абсолютно точным одновременно. T’ является безопасным подмножеством T тогда и только тогда, когда:

Если P и P’ выполняются в идентичных условиях и T’ является безопасным подмножеством T, исполнение T’ на P’ всегда обнаруживает любые связанные с изменениями ошибки в P, которые могут быть найдены путем исполнения T. Если существует тест, обнаруживающий ошибку, безопасный метод всегда находит ее. Таким образом, ни один случайный метод не обладает такой же эффективностью обнаружения ошибок, как безопасный метод.
При некоторых условиях безопасные методы в силу определения «безопасности» гарантируют, что все «обнаруживаемые» ошибки будут найдены. Поэтому относительная эффективность всех безопасных методов равна эффективности метода повторного прогона всех тестов и составляет 100%. Однако их абсолютная эффективность падает с увеличением интервала тестирования. Отметим, что безопасный метод действительно безопасен только в предположении корректности исходного множества тестов T, то есть когда при выполнении всех  исходная программа P завершилась с корректными значениями выходных данных, а все устаревшие тесты были из T удалены.
исходная программа P завершилась с корректными значениями выходных данных, а все устаревшие тесты были из T удалены.
Существуют программы, измененные версии и наборы тестов, для которых применение безопасного отбора не дает большого выигрыша в размере набора тестов. Характеристики исходной программы, измененной версии и набора тестов могут совместно или независимо воздействовать на результаты отбора тестов. Например, при усложнении структуры программы вероятность активации произвольным тестом произвольного изменения в программе уменьшается. Безопасный метод предпочтительнее выполнения всех тестов набора тогда и только тогда, когда стоимость анализа меньше, чем стоимость выполнения невыбранных тестов. Для некоторых систем, критичных с точки зрения безопасности, стоимость пропуска ошибки может быть настолько высока, что небезопасные методы выборочного регрессионного тестирования использовать нельзя.
Примером безопасного метода может служить метод, который выбирает из T каждый тест, выполняющий, по крайней мере, один оператор, добавленный или измененный в P’ или удаленный из P. Применение этого метода для регрессионного тестирования функции решения квадратного уравнения потребует построения матрицы покрытия, пример которой приведен в таблице на Рис. 12.1. Следует отметить, что матрица покрытия соответствует исходной версии программы, поскольку аналогичная информация для новой версии программы пока не собрана. Звездочка в ячейке таблицы означает, что соответствующий тест покрывает определенную строку кода; если тест не покрывает строку кода, ячейка оставлена пустой. Строки, измененные по отношению к исходной версии, выделены цветом. Легко заметить, что в соответствии с требованиями предложенного безопасного метода для повторного выполнения
должны быть отобраны тесты 1, 2 и 5.
Аннотация: Рассматриваются цели, задачи и виды регрессионного тестирования. Перечисляются необходимые и достаточные условия применения методов выборочного регрессионного тестирования. Дается классификация методов выборочного регрессионного тестирования и самих тестов при отборе. Рассматриваются возможности повторного использования тестов.
Цели и задачи регрессионного тестирования
При корректировках программы необходимо гарантировать сохранение качества. Для этого используется регрессионное тестирование — дорогостоящая, но необходимая деятельность в рамках этапа сопровождения, направленная на перепроверку корректности измененной программы. В соответствии со стандартным определением, регрессионное тестирование — это выборочное тестирование, позволяющее убедиться, что изменения не вызвали нежелательных побочных эффектов, или что измененная система по-прежнему соответствует требованиям.
Главной задачей этапа сопровождения является реализация систематического процесса обработки изменений в коде. После каждой модификации программы необходимо удостовериться, что на функциональность программы не оказал влияния модифицированный код. Если такое влияние обнаружено, говорят о регрессионном дефекте. Для регрессионного тестирования функциональных возможностей, изменение которых не планировалось, используются ранее разработанные тесты. Одна из целей регрессионного тестирования состоит в том, чтобы, в соответствии с используемым критерием покрытия кода (например, критерием покрытия потока операторов или потока данных), гарантировать тот же уровень покрытия, что и при полном повторном тестировании программы. Для этого необходимо запускать тесты, относящиеся к измененным областям кода или функциональным возможностям.
Пусть T = {t1, t2, …, tN} — множество из N тестов, используемое при первичной разработке программы P, а 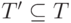 — подмножество регрессионных тестов для тестирования новой версии программы P’. Информация о покрытии кода, обеспечиваемом T’, позволяет указать блоки P’, требующие дополнительного тестирования, для чего может потребоваться повторный запуск некоторых тестов из множества
— подмножество регрессионных тестов для тестирования новой версии программы P’. Информация о покрытии кода, обеспечиваемом T’, позволяет указать блоки P’, требующие дополнительного тестирования, для чего может потребоваться повторный запуск некоторых тестов из множества 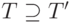 , или даже создание T» — набора новых тестов для P’ — и обновление T.
, или даже создание T» — набора новых тестов для P’ — и обновление T.
Другая цель регрессионного тестирования состоит в том, чтобы удостовериться, что программа функционирует в соответствии со своей спецификацией, и что изменения не привели к внесению новых ошибок в ранее протестированный код. Эта цель всегда может быть достигнута повторным выполнением всех тестов регрессионного набора, но более перспективно отсеивать тесты, на которых выходные данные модифицированной и старой программы не могут различаться. Результаты сравнения выборочных методов и метода повторного прогона всех тестов приведены в
таблица
11.1.
| Повторный прогон всех тестов | Выборочное регрессионное тестирование |
|---|---|
| Прост в реализации | Требует дополнительных расходов при внедрении |
| Дорогостоящий и неэффективный | Способно уменьшать расходы за счет исключения лишних тестов |
| Обнаруживает все ошибки, которые были бы найдены при исходном тестировании | Может приводить к пропуску ошибок |
Задача отбора тестов из набора T для заданной программы P и измененной версии этой программы P’ состоит в выборе подмножества  для повторного запуска на измененной программе P’, где
для повторного запуска на измененной программе P’, где 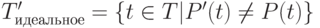 . Так как выходные данные P и P’ для тестов из множества заведомо одинаковы, нет необходимости выполнять ни один из этих тестов на P’. В общем случае, в отсутствие динамической информации о выполнении P и P’ не существует методики вычисления множества T’идеальное для произвольных множеств P, P’ и T. Это следует из отсутствия общего решения проблемы останова, состоящей в невозможности создания в общем случае алгоритма, дающего ответ на вопрос, завершается ли когда-либо произвольная программа P для заданных значений входных данных. На практике создание T’идеальное возможно только путем выполнения на инструментированной версии P’ каждого регрессионного теста, чего и хочется избежать.
. Так как выходные данные P и P’ для тестов из множества заведомо одинаковы, нет необходимости выполнять ни один из этих тестов на P’. В общем случае, в отсутствие динамической информации о выполнении P и P’ не существует методики вычисления множества T’идеальное для произвольных множеств P, P’ и T. Это следует из отсутствия общего решения проблемы останова, состоящей в невозможности создания в общем случае алгоритма, дающего ответ на вопрос, завершается ли когда-либо произвольная программа P для заданных значений входных данных. На практике создание T’идеальное возможно только путем выполнения на инструментированной версии P’ каждого регрессионного теста, чего и хочется избежать.
Реалистичный вариант решения задачи выборочного регрессионного тестирования состоит в получении полезной информации по результатам выполнения P и объединения этой информации с данными статического анализа для получения множества T’реальное в виде аппроксимации T’идеальное. Этот подход применяется во всех известных выборочных методах регрессионного тестирования, основанных на анализе кода. Множество T’реальное должно включать все тесты из T, активирующие измененный код, и не включать никаких других тестов, то есть тест входит в T’реальное тогда и только тогда, когда t задействует код P в точке, где в P’ код был удален или изменен, или где был добавлен новый код.
Если некоторый тест t задействует в P тот же код, что и в P’, выходные данные P и P’ для t различаться не будут. Из этого следует, что если 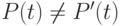 , t должен задействовать некоторый код, измененный в P’ по отношению к P, то есть должно выполняться отношение
, t должен задействовать некоторый код, измененный в P’ по отношению к P, то есть должно выполняться отношение  . С другой стороны, поскольку не каждое выполнение измененного кода отражается на выходных значениях теста, могут существовать некоторые такие , что P(t) = P'(t). Таким образом, T’реальное содержит T’идеальное целиком и может использоваться в качестве его альтернативы без ущерба для качества тестируемого программного продукта.
. С другой стороны, поскольку не каждое выполнение измененного кода отражается на выходных значениях теста, могут существовать некоторые такие , что P(t) = P'(t). Таким образом, T’реальное содержит T’идеальное целиком и может использоваться в качестве его альтернативы без ущерба для качества тестируемого программного продукта.
Важной задачей регрессионного тестирования является также уменьшение стоимости и сокращение времени выполнения тестов.
Рассмотрим отбор тестов на примере
рис.
11.1. Код, покрываемый тестами, выделен цветом и штриховкой. Легко заметить, что код, покрываемый тестом 1, не изменился с предыдущей версии, следовательно, повторное выполнение теста 1 не требуется. Напротив, код, покрываемый тестами 2, 3 и 4, изменился; следовательно, требуется их повторный запуск.
Рис.
11.1.
Отбор тестов для множества T’.